背景
公司内的 DNS 服务,是基于 CoreDNS 自研的,最开始只对这个项目做过一次代码 Review(发现过其处理泛域名解析存在逻辑 Bug )之后,就再也没有参与。而随着公司业务变化,疫情影响,负责这个 DNS 的事情落在我这里。
在此期间,运维那边发现,某个域名配置多个 A 记录之后,只有某一台机器承载了所有请求。后经排查,是所有请求,都打到了 DNS 记录中的第一个。经过测试发现,目前的 DNS 服务确实存在此问题,其自身的 DNS 记录,永远是有序的,也就意味着现有运维架构下的 DNS 服务是无法做负载均衡的,要做负载,其返回的 DNS 记录,必须是随机的。
经过 2 个小时左右重新梳理这套 DNS 服务源码和架构,迅速做了代码修复,跑了单测,并在 6.24 日(周三),做了一版 DNS 服务更新,不过,此次更新,是更新的办公区网络环境下的 DNS 服务,打算后续观测问题不大,再推到线上。
而最近 2 天(端午后的 周日、周一)出现多次办公区网络卡顿问题,因不确定是否和此次 CoreDNS 的改动有关。下面是具体的排查流程。
排查
1. 监控观察
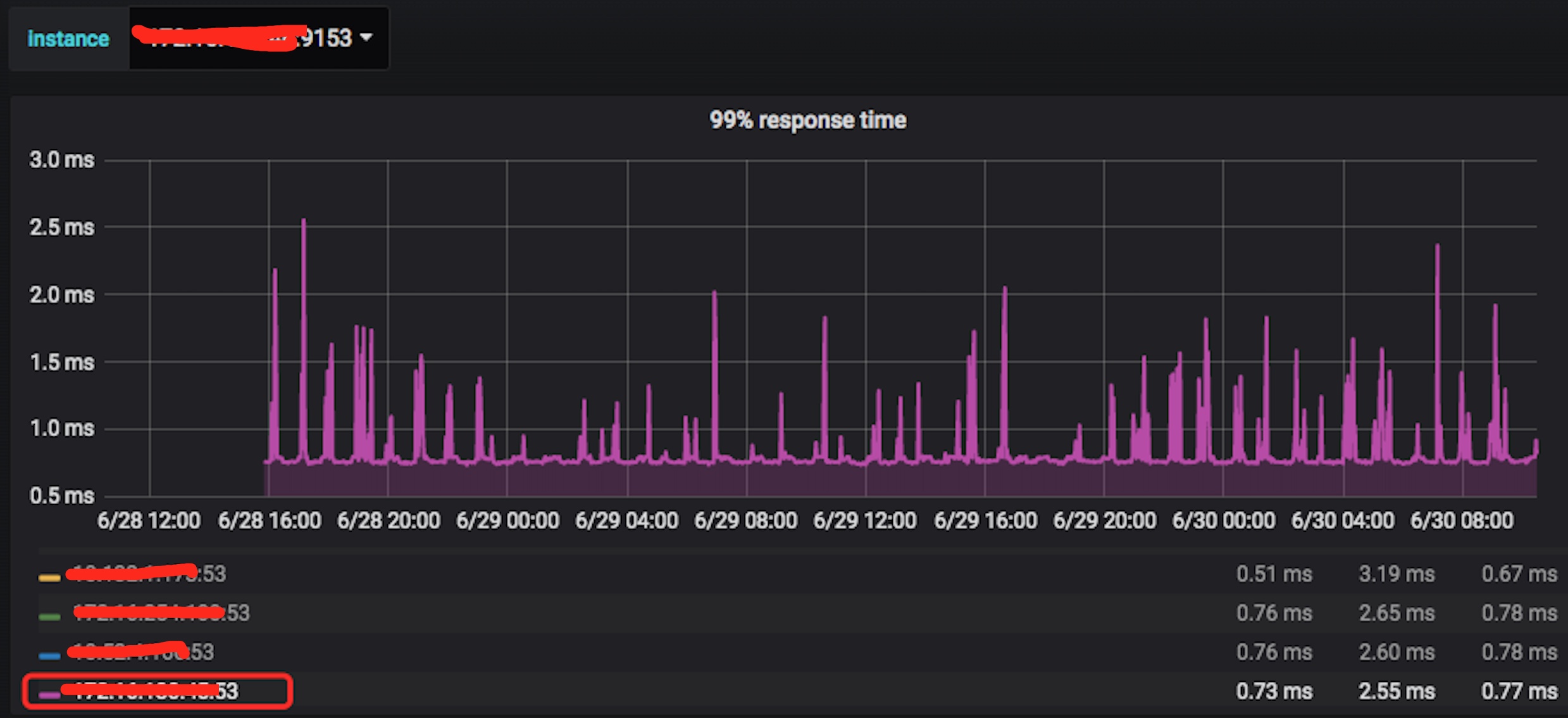
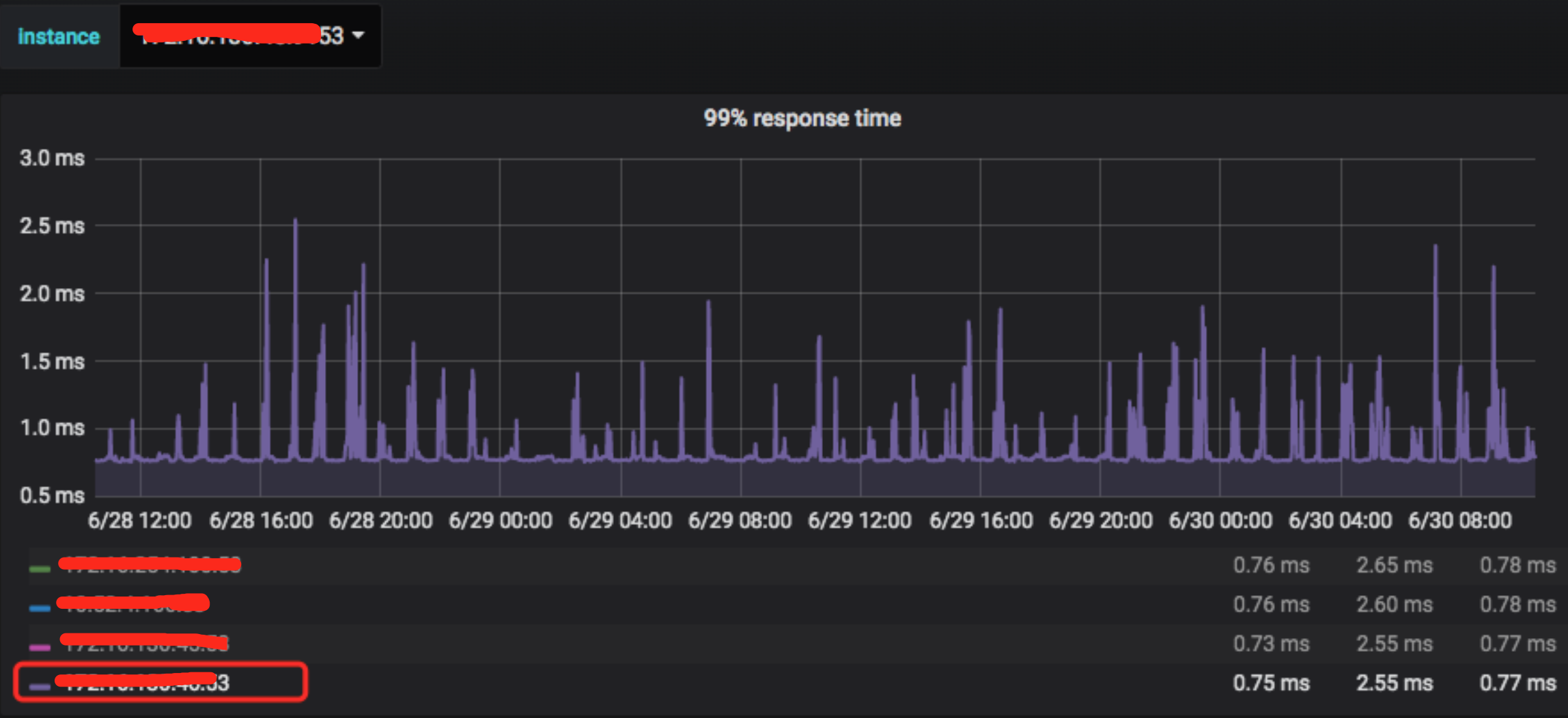
1.1 CoreDNS P99 响应时间
办公区 DNS 一共 2 台。下面是监控的 DNS 响应时间的 P99 响应耗时截图,从图中可以看出,任何时刻,P99 都是 2.5ms 以下:
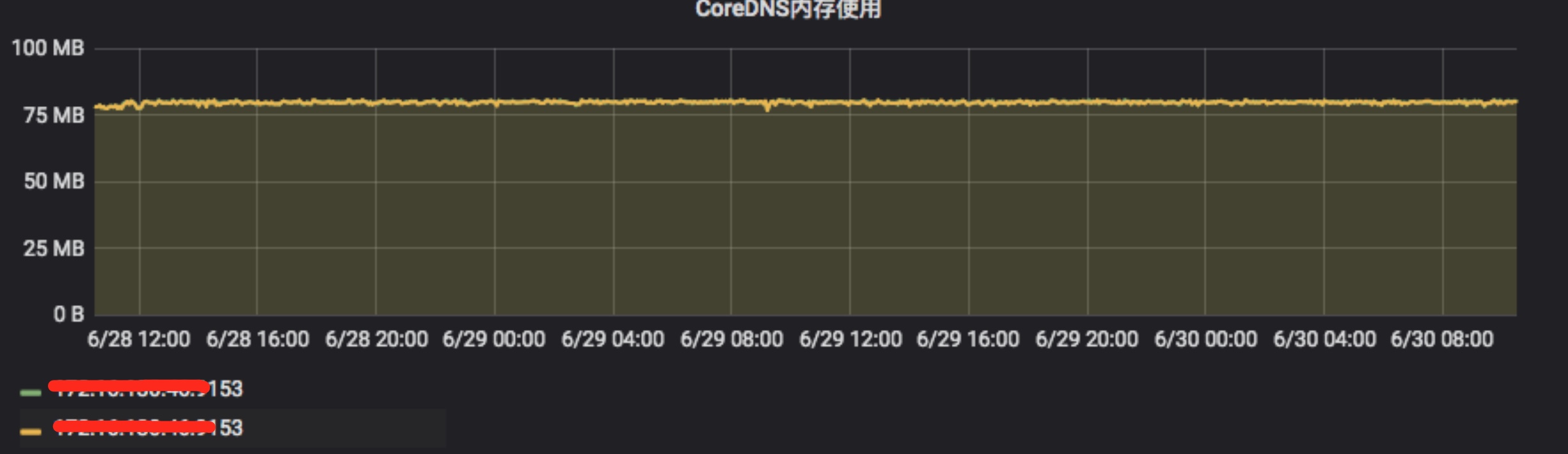
1.2 应用自身的内存使用,也没有明显波动
1.3 关于 GC 耗时:
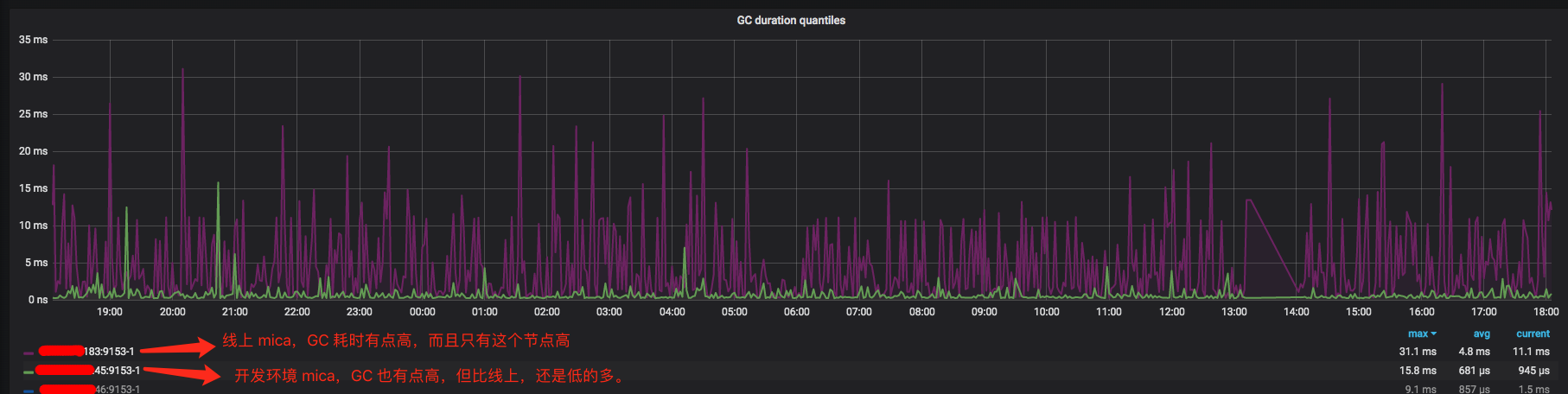
从这个 GC 耗时上看,开发环境的 CoreDNS 耗时,比线上某个节点低很多。所以,如果线上都不存在问题,开发环境这个 CoreDNS 的 GC 就不是问题。
不过,线上 CoreDNS 服务这个 GC,其实是有点高的,Golang GC 时,会 STW,此期间整个程序都无法响应外部请求。如此来看,线上节点这个 CoreDNS 服务 ,是可能导致业务 DNS 请求耗时高的。而这个线上节点的 P99 响应时间监控都正常,可能是因为 STW 时间段内,一切统计失效,连 metrics 都收集不上来(后续有结果再发文出来)。
2. 性能测试
按照上面监控来看,开发环境 CoreDNS 没什么问题。上次代码调整,其实只是加了一个 shuffle 函数
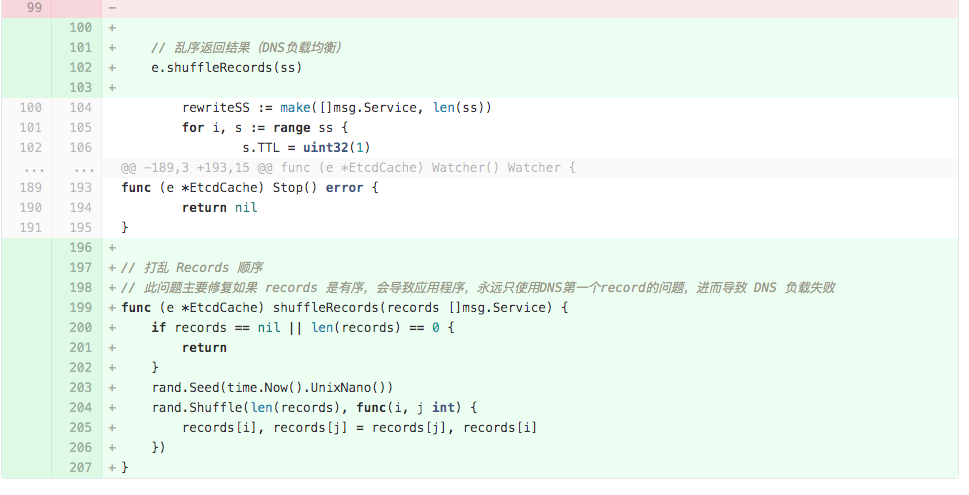
之前的测试,也只是做了功能测试和单测。也不觉得仅增加一个 shuffle(而且还是 Golang 内置函数)会影响性能。下面补一下加前后的性能对比,性能对比更具说服力。
其实 shuffle 函数的核心就 2 个:
- 生成随机种子
- 执行随机
2.1、加了随机处理 的性能测试(2次)
1 | Benchmark_EtcdCache_GetRandRecords-4 494914 11145 ns/op 224 B/op 3 allocs/op |
结果说明:
- 平均耗时:11149 纳秒(0.01 毫秒)
- 每次 3 次内存分配。
- 每次分配内存 224B。
2.2、未做随机处理 的性能测试(2次)
1 | Benchmark_EtcdCache_GetRandRecords-4 20001678 310 ns/op 224 B/op 3 allocs/op |
结果说明:
- 平均耗时:310 纳秒(0.0003 毫秒)
- 每次 3 次内存分配。
- 每次分配内存 224B。
两次性能测试对比说明:
单次处理时间看,加了随机后,性能慢了 35 倍,也就是慢了 0.01 毫秒。
虽然性能测试结果,随机与否,仅相差 0.0.1 毫秒,但需要找出来慢 35 倍的点,到底在什么地方。
3. 性能优化
3.1、先看原本的随机,是如何处理的:
1 | // 打乱 Records 顺序 |
说明:
- 此函数的随机处理,几乎是完全使用 Golang 内置函数 rand.Shuffle。
- 每次随机之前,都新播种一个随机数种子。经验告诉我:如果不播种随机数,那么,每次得到的随机值可能是相同的。
3.2 实测如果不每次做随机种子生成,而是程序初始化的时候只做一次,是否依然随机
1 | // 生成随机数在初始化的时候做,且只做一次 |
结论:既然随机(省去贴结果的步骤了)。
再做一次性能测试:
1 | Benchmark_EtcdCache_GetRandRecords-4 17109836 368 ns/op 224 B/op 3 allocs/op |
结果说明:这一次性能提升近 35 倍,相比不做随机处理,性能仅仅多出 60 纳秒(372-312),也就是:0.00006 毫秒。
另外,除了性能测试外,单测也通过,说明随机是有效的。
3. 引出疑问
很多文章都提到,随机数种子,对随机起了决定性作用。那么,如果仅在程序启动的时候生成一次随机数种子,那么不应该是每次函数调用,得到的随机结果都是一样的嘛,为什么单测的时候,依然能每次获取的结果是随机的呢?
如果你也有这个疑问,可继续往下看。
随机数,其实有 2 种:真随机数 和 伪随机数
真随机数
真正的随机数是使用物理现象产生的:比如掷钱币、骰子、转轮、使用电子元件的噪音、核裂变等等,这样的随机数发生器叫做物理性随机数发生器,它们的缺点是技术要求比较高。
伪随机数
真正意义上的随机数(或者随机事件)在某次产生过程中是按照实验过程中表现的分布概率随机产生的,其结果是不可预测的,是不可见的。而计算机中的随机函数是按照一定算法模拟产生的,其结果是确定的,是可见的。我们可以这样认为这个可预见的结果其出现的概率是100%。所以用计算机随机函数所产生的“随机数”并不随机,是伪随机数。
所谓随机数,其实是伪随机数,所谓的‘伪’,意思是这些数其实是有规律的,只不过因为算法规律太复杂,很难看出来而已。而,再厉害的算法,如果没有一个初始值,它也不可能凭空造出一系列随机数来,我们说的 随机数种子 就是这个初始值。
随机数的生成过程:
随机数是这样生成的:我们将这套复杂的算法(是叫随机数生成器吧)看成一个黑盒,把我们准备好的种子扔进去,它会返给你两个东西,一个是你想要的随机数,另一个是保证能生成下一个随机数的新的种子,把新的种子放进黑盒,又得到一个新的随机数和一个新的种子,从此可以不断的生成新的随机数。
总结来说,程序启动的时候,仅需要一个随机数种子,进行一次随机后,会自动生成新的随机数种子以保证下次随机操作的结果可以生成新的随机数。
因此,回到之前的程序上,其实我们并不需要在执行 rand.Shuffle 之前每次都生成一遍新的随机数种子,这个操作一定程度上说,对性能是有一些影响的。
而前面提到,随机数种子固定,随机结果固定,指的是横向角度。也就是说,只要随机数种子是一样的,纵向来看,的确每次随机的结果是不同的,但横向来看,所有的随机结果的确是相同的,如图:

可以看到:
- 纵向来看,每次结果,的确是随机了——随机数种子生成一次,后续每次随机操作的结果,均随机。
- 横向对比第一次执行和第二次执行的,每一次随机结果,是完全一样的——随机数种子固定,随机结果固定可复现。
