背景
有 2 个 K8s 集群, 网络模式不同,集群1 是虚拟网络 K8s(flannel vxlan)、集群2 是 L2 层网络 K8s(macvlan),之前,对 2 个集群的架构,做了调整,打通了 2 个集群的容器网络,做了互联互通(容器间可以跨集群网络调用)。
然后,很多服务,需要从集群1,迁移到集群2,最终目的就是容器部署在 L2 层网络 K8s 集群。
在迁移过程中,遇到一个问题,表现为:从虚拟网络某容器,访问 L2 网络的某容器,偶尔不通。
- src(虚拟网络容器,client端):10.144.76.9
- dst(L2层网络容器,server端):10.151.11.172,端口:8990
问题表现:
- ping 没有任何问题,一直都能通。
- 但是,telnet 10.151.11.172 8990 偶尔不通。
过程分析
1、抓包
从虚拟网络容器发出,请求目标容器
- src:10.144.76.9
- dst:10.151.11.172:8990
在目标容器内抓包,也就是抓目标 10.151.11.172 容器网络的报文,当 telnet 不通时,报文表现如下:
1 | 14:56:29.008806 IP 192.168.2.174.52506 > 10.151.11.172.8990: Flags [S], seq 3492286538, win 28200, options [mss 1410,sackOK,TS val 2320837474 ecr 0,nop,wscale 7], length 0 |
也就是,包从源容器发出去了,但目标容器没回包。导致请求调用者产生了 TCP 重试。( Linux 最多重试 5 次,也就是最多一共请求 6 次。( 1s->2s->4s->8s->16s->32s )
结论:目标容器收到了 SYN 包,但是没有回包!
2、验证 Java 服务是否正常
虽然从抓包来看,容器没回包做 ACK,但是可以抓包请求报文 SYN。另外,ping 没有问题,从这一层,猜测容器网络应该是正常的。可能是 Java 服务本身有问题。因为服务在高负载等情况下,是可能因为繁忙,无法处理正常 socket accept。
Java 服务监听的 8990 端口,也监听了 1234 端口。
在源容器无法 telnet 目标容器 8990 端口时,尝试 telnet 1234 端口,发现也不通。
为了验证到底是否为 Java 服务本身问题。在 Java 容器网络下(通过 nsenter 进入容器网络),起一个 golang 的 HTTP Server,相当于 Java 服务 + Golang 服务共用容器网络,但是 Golang 服务进程,不在 Java 服务的容器环境里(因此,不受 Cgroup 约束,直接使用宿主机资源)。
结果:
- 在源容器无法访问目标容器 8990 端口时,也无法 telnet 9944 端口(golang服务端口)。
- 此时,迅速找个其他物理机,访问目标容器 9944 端口,发现是正常的。
- 即便是在源容器所在主机,访问目标容器 9944 端口,也不正常。
- 从容器及其物理机都无法访问目标容器来看,好像问题仅出现在请求方容器和其所在物理机。
另外,查看 Java 服务的监控,从 CPU、内存、Load 来看,Java 服务本身,负载并不高。
结论:和 Java 服务,无关!
3、不是 server 服务问题,可能就是 server 的操作系统问题
google,找到一些文章,说是,如果机器,在内核中,如果同时开启了下面 2 个内核参数,可能会导致 TCP 建联过程中,Server 端不做 ACK!
1 | net.ipv4.tcp_tw_recycle |
Server 端当 tcp_tw_recycle 和 tcp_timestamps 都是1的时候,Server 端,会检查收到数据包 TCP 选项字段中的 timestamp(TS Value),当来自同一个IP地址(任意源端口号)后来的数据包中TCP选项字段如果有 timestamp 且比前面的数据包中的 timestamp 小,则 Server不做 ACK 响应。
查看了一下,在目标容器所在的主机,进入目标容器网络,看下的 reject 包
1 | [root@node10-151-11-1 donghongshuai] |
可以看到有很多因为 timestamp 导致的报文被拒绝问题。而且,这个值的数量,还在持续增加。
关闭 tcp_tw_recyle( 目的是,不同时开启 tcp_timestamps 和 tcp_tw_recycle,关闭一个就行了 )
1 | // 在 目标服务器主机上,临时关闭 |
观测 reject 报文,确实已经不再增加
1 | // 调整后,经过一段时间,再次执行,发现 351763 这个值不再增加了 |
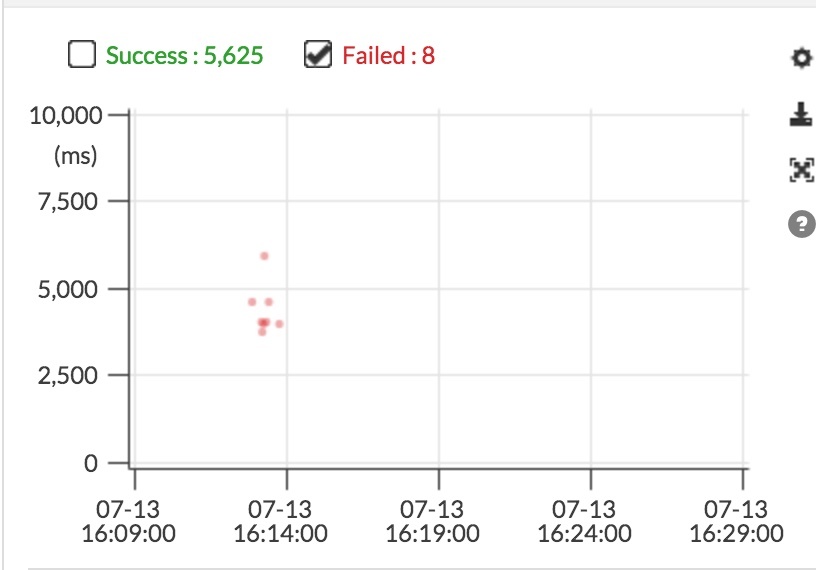
再通过全链路跟踪观测,从调整之后(16:14),就再也没有出现 Failed 。
结论
1、Server 端所在物理机内核参数问题。
2、Linux Server 端内核,不要同时开启tcp_timestamps、tcp_tw_recycle以防止 TCP 建连失败。
4、疑惑解读
为什么 ping 可以,telnet 不行?
是因为,ping ,是 ICMP 报文,ICMP 是无链接协议。telnet 是基于 TCP 的,TCP 是链接协议。
而上面的 tcp_tw_recycle、tcp_timestamps 都是针对 TCP 的,所以,reject 的报文的时候,也是 reject TCP 报文。
因此,表现为 ping 一直是通的,telnet 偶尔不通。
扩展
tcp_tw_recycle + tcp_timestamps 的用途
Server 端当 tcp_tw_recycle 和 tcp_timestamps 这 2 个内核参数的值都是 1 的时候,Server 端,会检查收到数据包 TCP 选项字段中的的 timestamp(TS Value),当来自同一个 IP 地址(任意源端口号)后来的数据包中 TCP 选项字段如果有 timestamp 且比前面的数据包中的 timestamp 小,则Server不做 ACK 响应。
net.ipv4.tcp_timestamps
tcp_timestamps 的本质是记录数据包的发送时间。基本的步骤如下:
- 发送方在发送数据时,将一个 timestamp (表示发送时间)放在包里面
- 接收方在收到数据包后,在对应的 ACK 包中将收到的timestamp 返回给发送方(echo back)
- 发送发收到 ACK 包后,用当前时刻 now - ACK 包中的 timestamp 就能得到准确的 RTT
timestamps 是一个双向的选项,当一方不开启时,两方都将停用 timestamps。
比如 Client 端发送的 SYN 包中带有 timestamp 选项,但 Server 端并没有开启该选项。则回复的 SYN-ACK 将不带 timestamp 选项,同时 Client 后续回复的 ACK 也不会带有 timestamp 选项。当然,如果 Client 发送的 SYN 包中就不带 timestamp ,双向都将停用 timestamp。
net.ipv4.tcp_tw_recycle
tcp_tw_recycle 主要是解决 TIME_WAIT 的问题。TIME_WAIT 多会有什么问题?
其实,TIME_WAIT 这个状态,出现在主动端口 TCP 链接,也就是主动对 TCP 链接做 Close 的那一端。TIME_WAIT 占用的1分钟时间内,相同四元组(源地址,源端口,目标地址,目标端口)的连接无法创建。
主动 Close TCP 的那一端一般都是 Client 端,Server 端主动 Close 的情况比较少(也有,比如 MySQL 主动断开链接)。所以,客户端能用的端口,一般是 net.ipv4.ip_local_port_range 指定的 32768-61000 ,故而,TIME_WAIT 可能导致这个范围的端口被占用而慢慢耗尽。耗尽之后,就不能再主动发起 TCP 链接了。
为解决此问题,Linux 引入了 tcp_tw_recycle (本文提及的)和 tcp_tw_reuse 。而且,这俩,都要和 tcp_timestamps 一起来使用(这几个都需要手动开启,默认是关闭的,也就是值为 0 )。
那么,tcp_tw_recycle + tcp_timestamps 与 tcp_tw_reuse + tcp_timestamps 有什么区别?
| 分类 | 影响链接类型 | 影响发起/接受方 | 特点 |
|---|---|---|---|
tcp_tw_reuse + tcp_timestamps |
连出的连接 | 客户端(连接发起方) | TIME_WAIT 创建时间超过 1 秒才可以被复用 |
tcp_tw_recycle + tcp_timestamps |
所有连入和连出的连接 | 客户端+服务端 | Linux会丢弃所有来自远端的 timestramp 时间戳小于上次记录的时间戳(由同一个远端发送的)的任何数据包。 |
综合来看,tcp_tw_reuse + tcp_timestamps 更安全一些。
另外,Linux 从 4.10 内核开始,官方修改了时间戳的生成机制。在这种情况下,无论任何时候,tcp_tw_recycle 都不应该开启。tcp_tw_reuse 选项仍然可用,在某些情况下,可以考虑打开。
