背景
谈论问题,先谈背景。
K8s 在虚拟网络下存在很多问题。比如说:
- Pod IP 无法被外部访问,只能在 K8s 集群内访问。直接从实例上无法做到与物理机实例互联互通。
- Java 等依赖外部注册中心的服务,如果不放到同一个 K8s 集群里,服务之间无法互访。
- 复杂场景下,比如:多机房、集群灾备等,需要多 K8s 集群。原生 K8s 集群下,每个集群网络都是虚拟的,多个虚拟网络要互通。如果是 flannel 的话,可以借助同一个 etcd 来实现多 K8s 集群的 Pod 互通,但是 service ip 可就不行了,依然是个问题。
- 以应用中心为视角来看,从上层架构来说,底层 instance 具备可访问行,不论是容器实例,物理机,还是虚拟机实例,都应该具备可访问属性。而虚拟网络下的容器实例,违背了这一点。
所以说,K8s 虚拟网络模型,需要变迁到 K8s 2层容器网络模型。改造为2层网络的方式主要处理几个点:
- 从 CNI 中,选择容器网络2层化方案。
- 从 CNI 中,选择合适的 IPAM 方案。
K8s 官方的 CNI 中,能比较好的支持容器2层网络方案的,比如:bridge + veth pair、macvlan、ipvlan 等。而 IPAM ,可以说最基本的就是 host-local 方案了。
简单比较一下 bridge 模型和 macvlan 模式
bridge 就是虚拟交换机:网桥。从一些资料来看,如果单纯的说 bridge,其本身性能还是很高的,但是 bridge 下挂 veth pair,整套连起来运作,veth pair 会拖累 bridge 的性能表现。这样一来,就远没有 macvlan 性能高了。我们参考几组数据:
1、macvlan bridge 模式,对 CPU 负载的消耗,bridge 模式占用 CPU 资源最高。
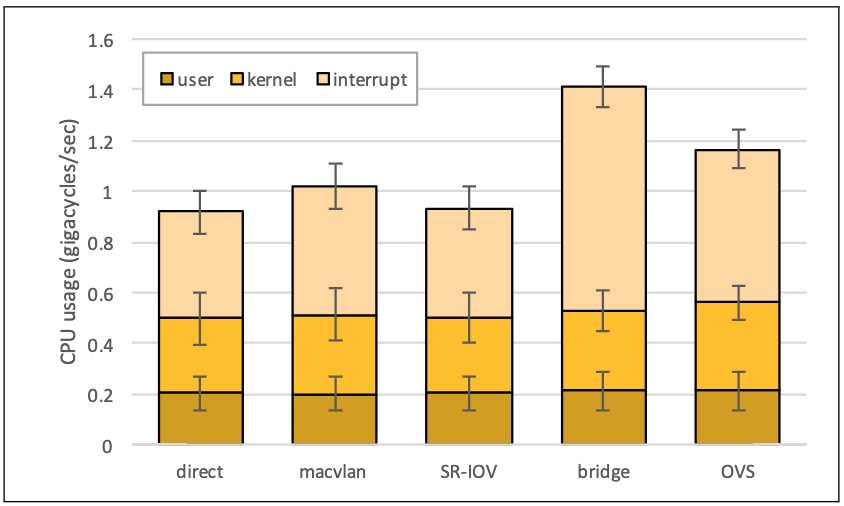
2、对比 macvlan、bridge、OVS 及 Native Host 的性能
注意:CHC 表是的是,同主机上 Container->Host->Container 模式。CHHC 表是的是跨主机:Container->Host->Host->Container 模式。
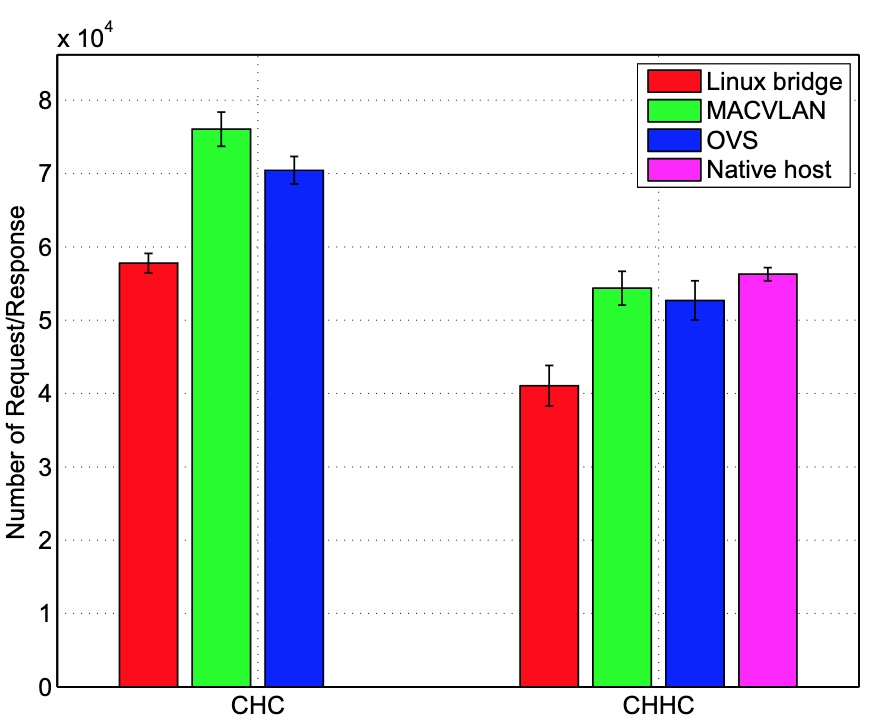
可以看到,macvlan 模式下,不论是同主机间的容器互访,还是跨主机间的容器互访,其单位时间内的请求/响应量级都很高,几乎接近主机网络(Native Host)。
再来看一下吞吐量(容器互访,横坐标为TCP)
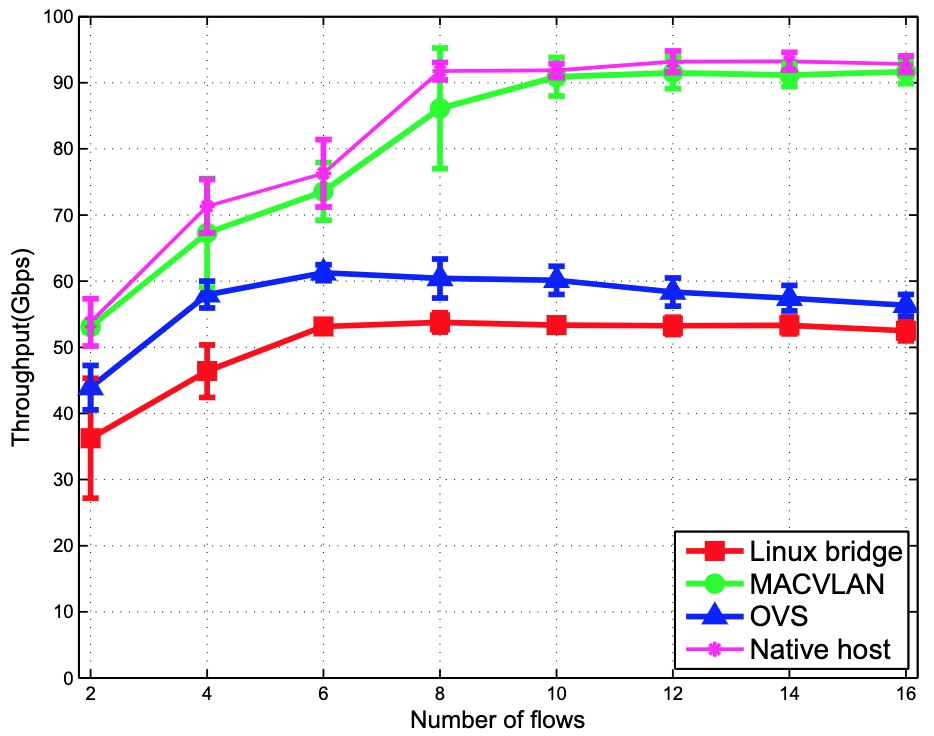
更详细的评测数据,可以参考:performance of container networking.pdf
总的来说,从某个角度看,macvlan 就是要替换 bridge + veth 模式的,就好比,macvtap 就是要替换 bridge + tap 模式的,macvlan 和 macvtap 只是用在场景不同而已。而我们团队,出于性能考虑,目前开发环境、线上环境,CNI 插件都是用 macvlan 做的2层容器网络,IPAM(IP Address Management) 模式,使用的是简单的 host-local(本机分配) 模式(后期要调整)。
是的。这里提到,“我们团队”。其实,在整个公司中,做 K8s 团队的不止我们一个。其他团队的实施,还主要以 flannel 虚拟网络为主。目前来说,2个团队现在已经整合为一个部门的团队,所以,K8s 基础设施也要统一,恰好,其中重要的一环,就是将现在虚拟网络的 K8s,也改造为 L2 层网络的 K8s 。目的主要有3个:
- 底层设施层面,统一 K8s 集群。不要虚拟和2层都有,增加维护成本。
- 在上层部署系统层面,由一套统一的部署系统,分别对接底层的 K8s。这就要求底层的 K8s 是统一的。
- 更上面的各种抽象模型统一,比如,对接服务到应用中心,而应用中心下的 instance 模型,要求 instance 实例都在 2层网络下,这样一来,围绕应用中心展开的:配置中心、发现中心、监控告警,都对接 2 层 instance 实例,就好开展了。
好了,问题来了:
- 虽然 K8s 集群做成 L2 K8s 不是很复杂的事儿,但是改造完得迁移服务。
- 迁移的过程,不是强制将原集群的实例,部署到新集群里,这个过程,是用户部署的动作来触发,应该是平滑的,对其业务无感知的。强制从1个集群迁移到另外一个集群,风险太高。
- 要保证业务平滑,必须会遇到一个现实问题:部分服务在虚拟网络 K8s 中,部分在2层网络 K8s 中。虚拟网络 K8s 集群里的实例访问 K8s L2层网络下的实例还好,不会有问题,但是,反过来,可就访问不通了(原生 K8s 虚拟网络的所有实例的可访问性,是只有集群内部生效的)。
所以,一个问题摆在眼前:K8s 虚拟网络,要和 K8s L2 层网络打通。这样才能保证新部署的服务,部署到 L2 层 K8s 集群里之后,它还可以访问到原来那个 K8s 虚拟网络下的实例。这一点对 Java 这种要通过注册中心,走RPC调用的服务,尤为重要。
注意:本文说的打通,其立场,是 2 个集群打通,而不是一个 L2 层网卡的 K8s 集群,要和多个 虚拟网络 K8s 集群打通。
K8s 虚拟网络(flannel)和 L2 层网络(macvlan)
L2 macvlan 网络
要做 2 个不同网络集群的打通,macvlan 网络最简单,简单理解为一个网桥就好,实际上,我们的 macvlan 就是用的 bridge 模式。
下面是 K8s 基于 macvlan 网络的一个简单架构图:
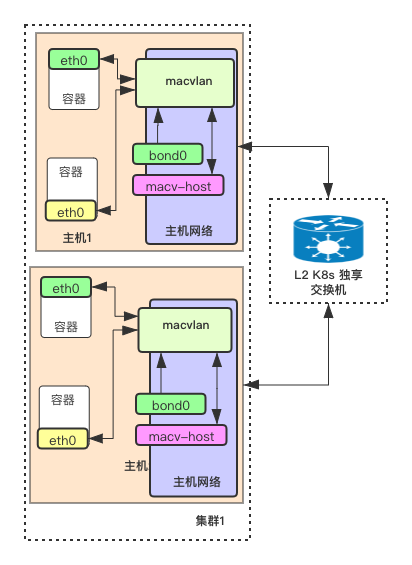
这个网络模式有几个核心的点:
- 容器之间,是可以通过 macvlan 互访的,不需要借助外部交换机。所以,macvlan 模式,用的是 bridge 模式,而不是 vepa 模式,vepa 模式的话,需要交换机开启“发夹”模式,对于我们的场景来说,没有必要在交换机上做这个事情,另外,交换机上还没有统一管理规则的需求。
- macvlan 的父接口,是 bond0,bond0 是做了网卡聚合的。可以提高带宽。
- 宿主机网络上,有一个 macv-host 网卡。这个网卡其实是 macvlan 的一个子接口,其目的,是为了实现宿主机与容器互访,这一点非常重要。
- K8s 集群的交换机是独享,且做了高可用的。为了应对以后容器数量增长提前做的准备。
- 我们是自建机房。如果是云服务器的话,macvlan 模式可能不一定用的了。因为 macvlan 依赖网卡特性以及网卡的混杂模式,这些特点,云服务器不一定支持。云服务器的话,可以考虑云服务厂商提供的现成的,且与 VPC 良好集合的方案。
flannel 网络
flannel 网络,相对于 macvlan 网络来说,要复杂一些。
flannel 网络,是 CoreOS 团队为 K8s 打造的一款用于解决 POD 跨主机互访的网络实现。它是一个 overlay 网络,是构建在 L2 层网络之上的虚拟网络。每一个 Pod 实例,都有一个虚拟 IP 地址。
下面一是 flannel 的网络架构图:
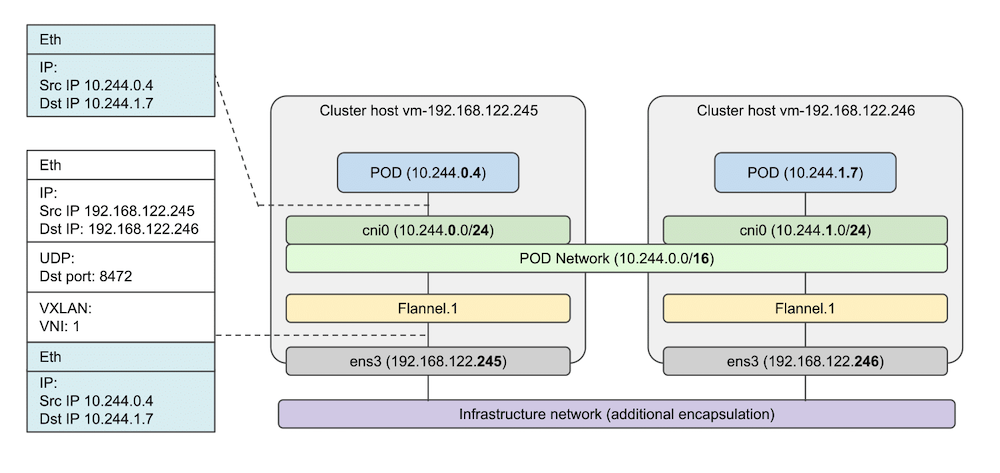
这个网络模式有几个核心的点:
- 在主机上,flannel 的守护进程 flanneld 在启动之后,会创建一个 flannel.1 的网卡(如果是 vxlan backend 的话)。它的作用,就是为了容器跨主机访问做封包、解包、创建整个 POD 网络互访需要的路由规则等内容的。要点:解决容器跨节点通信。
- 在主机上,还有一个 cni0 网卡。它的作用,和 docker 本身网络下的 docker0 作用是一样的,它们都是网桥 bridge。目的是解决容器在同一个主机上通信的。另外,cni0 这个网卡,并不是 flannel 启动的,确切的说,它是 K8s flannel 的这个 CNI 插件(在第一次创建 Pod 的时候)创建的。
- flannel 网络是一个虚拟网络,容器的流量要出访,必须经过 flannel 做封包处理,这也是 overlay 网络的特点。flannel vxlan 是做的 UDP 封包。
如果在 L2 层 K8s 网络里引入 flannel 网络,必须理清几个点
打通 2 个网络的方案中,是可以考虑,在 L2 层 K8s 中,引入虚拟网络这种方案的。如果是这种方案的话,flannel 网络下 K8s 用的组件,是不一定都得用在 L2 层 K8s 网络里的。因此,要理清几个点:
①:访问虚拟网络 POD 实例,就一定需要知道目标实例在哪个物理机节点。这个是谁来维护的(flanneld 守护进程)。
②:只是知道谁来维护 POD 网络信息还不行,必须得具备访问虚拟网络的能力,这就依赖 flannel 的 网卡:flannel.1 。这个网卡,也是 flanneld 守护进程创建的。
③:通常 flannel 网络里,还有一个 cni0 网卡,它要解决的点是同一个主机上容器互通的。而 L2 层 K8s 集群访问虚拟网络 K8s 集群,是要跨节点访问的,所以,L2 层网络的 K8s 下,cni0 网卡并不需要。
因此,从表现上来看,如果我们的方案是在 L2 层 K8s 里起虚拟网络 flannel 的话,只用 flannel 网络里的 flanneld 进程,而不用 flannel 网络下的 CNI 插件。
实施方案
关于打通 2 个现有不同网络模式的 K8s 集群,做到实例互通,其实最大的点在于,对哪个集群做改造。L2 层网络的 K8s 是基于 macvlan 来做的,这种模式的 K8s 下,容器 IP 就和虚拟机 IP 一样,可以认为 L2 层网络的 K8s 下的容器,就和现有的物理机、虚拟机一样。因此,这个问题的本质就成了:如何让 L2 层网络的 K8s 可以访问到虚拟网络的 K8s 实例。
方案有3个:
方案1:通过 VPN 的方式
VPN,在 L2 层网络的每一个节点,通过 VPN 的方式接入虚拟网络中。所以,需要虚拟网络 K8s 的某个节点开启 VPN Server,2 层网络的每一个 K8s 节点,都通过 VPN Client 接入到虚拟网络中。这种方式,有2个弊端:
- 原来的虚拟网络集群的某个节点,得起一个 Server,这个 Server 所在节点,要承载 2个 集群的所有互访流量。这个 Server 所在主机的网络带宽可能会成为瓶颈,另外,Server 一旦挂了,2个集群的互通,全部中断。
- L2 层网络 K8s 的所有节点,都得启动 VPN Client。这也是个维护成本。
方案2:找几个节点,做路由转发,相当于路由器的角色。
这个方案的主要核心在于,在虚拟网络 K8s 中,挑选几个节点,作为路由器角色,暂且称之为中转节点。L2 层网络K8s 访问虚拟网络 K8s 的流量,都经过这几个中转节点。中转节点,必须要在虚拟网络 K8s 中。访问模式为:2层容器->中转节点->虚拟网络容器。这个方案,如果可以实施的话,还是会存在中转节点是网络瓶颈的问题(但是比方案1好多了)。
方案3:将 L2 层网络的 K8s 集群的节点,全部加入到虚拟网络 K8s 的网络中。
这个方案的本质是,在 L2 层网络下的 K8s 节点上,部署 flannel 的组件。从网络层的角度看,L2 K8s 集群的实例,即属于 macvlan 2层网络,又属于 flannel 虚拟网络。但是这里有几个细节是要注意的:
- L2 K8s 集群部署的 flannel 其实是需要在每个节点都部署的。
- L2 K8s 节点上的 flannel,其职责,只是为了启动 flannel.1 这个虚拟网卡,这个网络的职责,就是承担 L2 K8s 节点实例,访问虚拟网络的一个桥梁。
- flannel 组件,必须,且不能干预到 L2 层 K8s 体系内的 2 个角色:Docker 、CNI。之所以提这个点,是因为,flannel 的部署往往和容器的 IP 分配耦合在一起。尤其是 flannel 官方提供的部署工具中,还有操作 docker 的脚本。这个是不需要执行的。
上面的3个方案,最终的落地方案是:方案3 。原因是操作简单,没有任何节点成为整个方案的瓶颈。
最终方案中,要解决及不准备解决的问题
- 虚拟网络 K8s 下的容器,访问 L2 层 K8s 下的容器和物理机。( 要解决,且天然就没有屏障)
- L2 物理机访问虚拟网络容器。(要解决)
- L2 容器访问虚拟网络容器。(要解决,注意,这里没和第 2 点放到一起,是因为这个问题解起来不一样)
- L2 容器和物理机访问虚拟网络 service vip 。(不解决)
关于在 L2 层 K8s 中,【不打算】支持访问 flannel 虚拟网络里的 service ip 的理由如下:
①:目前,需要网络里的服务,不需要靠 K8s service ip 来调用。比如:Java 体系内的 Spring Cloud 实例互访就不需要 service 。
②:L2 层网络 K8s 访问虚拟网络 service ip,相当于动作比较大,需要在 L2 层 K8s 部署 kube-proxy ,且这个 kube-proxy 要指向到另外一个虚拟网络集群的 kueb-apiserver 上。仅为支持这样一个弱需求,就要增加了整体架构复杂度。且,如果在 L2 层 K8s 里引入其他集群的 kube-proxy,它会新生成很多的 iptables 规则,有碍于现有 L2 层 K8s 的整体性能。
③:在一个纯 L2 层的 K8s 网络里,支持 service ip ,并不是说起了 kube-proxy 就完了,这和 flannel 不一样。后边会专门开心的文章,将如何在 L2 层 K8s 对 service ip 的访问支持。
最终方案架构
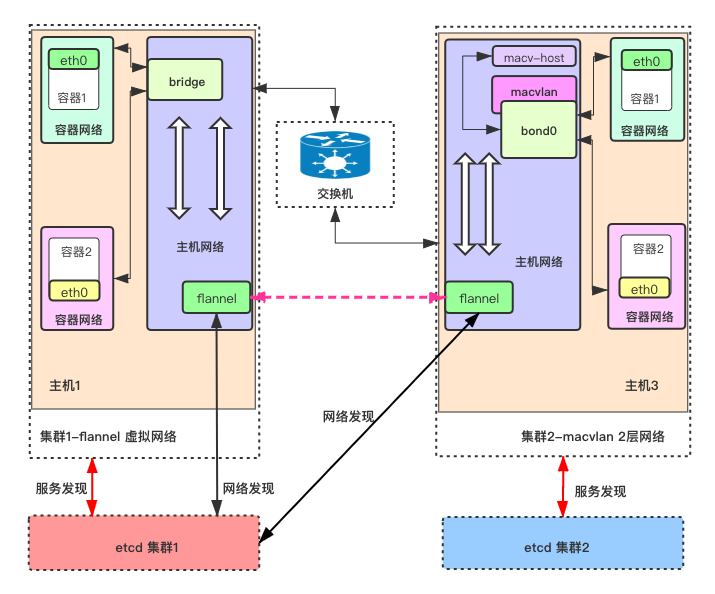
说明:
- 左图为基于 flannel 的虚拟网络集群,右图为基于 macvlan 的 2层网络集群。
- flannel 的网络相对经典,主机内容器互通(比如 集群1中,容器1 和容器2 互通),唯一的依赖就是网桥:bridge。
- macvlan 网络类似,主机内容器互通(比如 集群2中,容器1 和容器2 互通),唯一的依赖,就是 bond0(网卡聚合),这里要注意,bond0 已经成了 macvlan 下的虚拟交换机,类似于网桥,和 bridge 最大的区别有2个,一个 macvlan 相比 bridge 来说,交换性能更高,另外就是,主机若要访问主机上的容器,必须借助基于 bond0 生成一个宿主机的新网卡(子接口):macv-host。
- 主机内,不同网络的流转,借助主机内的路由表和 iptable。
- 集群2(2层网络)里的物理机,若要访问集群1(虚拟网络)里的容器。需要在2层网络集群的节点上,搭建 flannel。这个 flannel 版本、配置,和集群1里的 flannel 一样,并且使用同一套 etcd 集群,如上图。所有 flannel 基于 集群1 里的 etcd,共享网络发现能力和数据。所以,flannel 的职责非常清晰,只有3个:网络发现+同步路由表+overlay包处理。这种方式,解决了 L2物理机访问虚拟网络容器 这个点。
- 集群2(2层网络)里的容器,若要访问集群1(虚拟网络)里的容器,除了上面的工作之外,还需要一个事儿,那就是让集群2里的容器,知道如何访问集群1的网络。因此,需要将集群2的 K8s macvlan CNI 做一个配置,将访问虚拟网络的路由表,配置进去,且这个对虚拟网络的路由表依赖的网关,设置为当前物理主机。换句话说,当前主机,要充当路由器的角色。
2层K8s里的容器访问虚拟网络的流量的数据流为:
2层网络 K8s 容器->流转到当前物理机->主机路由表->主机flannel->出2层K8s的节点->到虚拟K8s的节点->节点路由表->节点bridge网桥->虚拟网络容器内部。
补充
1、贴一下 L2 层 K8s 节点最终的 CNI 配置
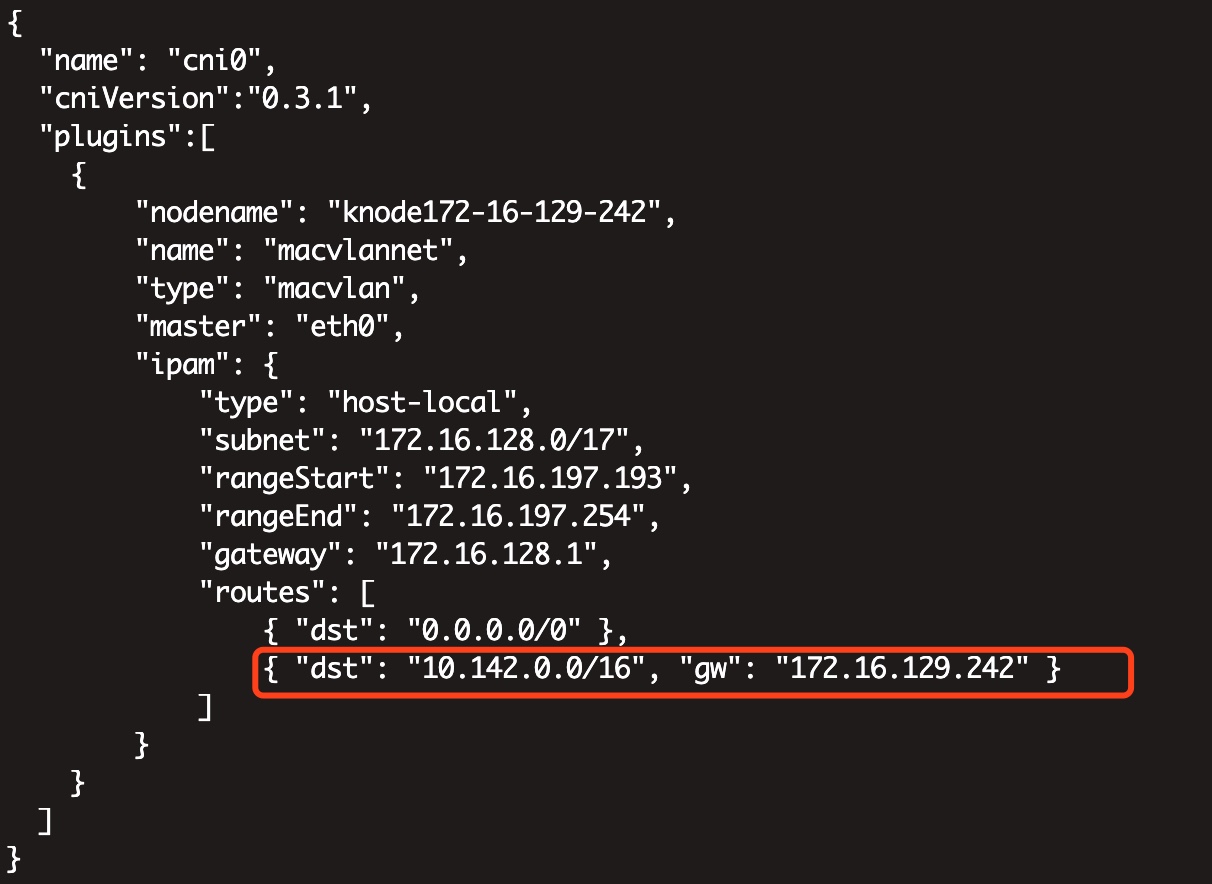
这个是 L2 K8s CNI 必须要做的一个配置,其目的是,让 L2 K8s 里启动的容器里,包括一个路由表,告诉其如果访问的网络是虚拟网络的 IP 端口的话,流量不要走原来的网关,而是走到当前节点的物理机上。
另外,L2 K8s 节点还要做几个事儿:
- Linux 上 必须开启 ip_forward。
- iptables 中也要适当做放行,也就是说,需要在 FORWARD 链添加 ACCEPT。
上面的2个点如果不做处理的话,发往虚拟网络下容器的流量,到了宿主机之后,也会被丢弃。
2、一些参考
https://www.lijiaocn.com/%E6%8A%80%E5%B7%A7/2017/03/31/linux-net-devices.html
https://blog.huiyiqun.me/2016/11/24/virtualization-with-libvirt-kvm-and-macvtap.html
https://events.static.linuxfound.org/sites/events/files/slides/LinuxConJapan2014_makita_0.pdf
https://cs.nju.edu.cn/tianchen/lunwen/2017/sgws-Zhao.pdf
https://tigerprints.clemson.edu/cgi/viewcontent.cgi?article=1034&context=computing_pubs
https://www.cnblogs.com/echo1937/p/7249037.html
https://blog.51cto.com/dog250/1652063
https://www.praqma.com/stories/debugging-kubernetes-networking
https://msazure.club/flannel-networking-demystify
