CNI 和 IPAM 概述
我们常说的CNI,可以包括IPAM(IP地址管理),也可以不包括IPAM。不过,通过情况下,CNI插件的实现和 IPAM插件的实现是分开为不同的可执⾏⽂件的。但是如果你写到⼀起,这样的CNI也可以⽤。按照K8S本⾝规 范,我们在使⽤CNI的时候,是要区分CNI和IPAM的。
K8S 启动 POD ⽹络的配置流程是,kubelet->docker(pause)->cni->ipam。因此,K8S⽹络的中⼼,便是 CNI 插 件和 IPAM 插件。因为 CNI 和 IPAM 插件很多,所以不打算都讲⼀讲。整体来说,CNI + IPAM 的实现可以分为2 类:
①:第⼀类:与宿主机平⾏⽹络(2层⽹络或3层⽹络)
②:第⼆类:利⽤ SDN 技术的虚拟⽹络
⽽第⼀类的 CNI ⽹络插件,主要是:bridge、macvlan、ipvlan、calico bgp、flannel host-gw 等。第⼆类的⽹络 插件主要有:flannel vxlan、calico ipip、weave 等。
虚拟SDN网络的优势和劣势
⼤部分使⽤K8S的公司,都是使⽤的K8S经典⽹络模型,⽐如:K8S+Flannel(VXLAN)、K8S+Calico(IPIP) 等。这种模式下的⽹络有⼀个共同特点,就是容器⽹络在K8S集群内是隔离的,集群外的宿主机是⽆法直接访问容 器IP的。之所以会这样,是因为容器⽹络是虚拟的,它这个K8S的虚拟⽹络,⼤部分上都是借助 路由表 + iptables + 隧道 模式来做的。
这种经典的⽹络模式,有优势,也有劣势。
优势1:⽹络隔离。
这种模式下,K8S集群内的节点的容器,是集群外宿主机节点⽆法访问的,所以,它能很好的起到隔离性的作⽤。 在有些公司这种模式⽐较好,⽐如:为多客户服务的公有云⼚商。另外,不同K8S的集群⽹络隔离,各个集群完全 可以使⽤同⼀个虚拟IP段,没有太多IP地址分配和管理的痛苦。
优势2:部署⽅便。
虽然这种⽅式很多公司会使⽤flannel vxlan模式的⽹络插件,或者calico ipip模式的⽹络插件,这2个插件的部署存 在⼀定复杂度,但是这种经典⽹络模式,有⾮常多的⼀键部署⼯具。⽐如:https://github.com/kubernetes-sigs/kubespray。
劣势1:⽹络隔离。
⽹络隔离,既是优势,也是劣势。关键还是看公司的使⽤场景是什么。如果是公有云,就有⼀定优势,但如果是私 有云,⽐如⼀个公司做整个容器平台。后期遇到的痛点之⼀,就是⾮K8S集群的机器,如何访问K8S集群内容器的 IP地址。
这⼀点可能很多⼈说不要直接访问容器IP就⾏了,但问题在于,业务的发展往往超过预期,搞K8S的部分,往往都 是基础架构部,或者系统部,但问题在于,这种部分,是⽀持部门,其职责之⼀,就是更好的⽀撑业务发展的多变 性。举个例⼦:如何让 Java 的服务,既可以部署到K8S集群内,还可以使⽤ Spring Cloud 或者 Dubbo+Zookeepr 这种服务发现架构?你可能会说,Java 的微服务要么⽤它们⾃⼰的体系,要么⽤ K8S 体系就⾏了,这就是⽀持部 分,⽀持的程度不够了。
换句话说,⽹络隔离,对公司多技术语⾔和其语⾔⽣态的的发展,存在⼀定阻碍。
劣势2:流量穿透的情况。
K8S 内虽然是⽹络隔离的。但其隔离的并不彻底。它的隔离性,原来的是 kube-proxy 组件⽣成的⼤量 iptables 规 则和路由表来实现的。这种模式下,iptables 的动态变化,其实依赖 kube-proxy 这个组件,⽽这个组件,其实监 听的 K8S 集群的 service + endpoint 资源。我们部署在集群内的服务,访问某个内部服务,⽤的是基于 DNS 的服 务发现机制。这就带来了下⾯⼀个问题:
如果服务A访问服务B,必先经过 DNS 解析拿到 service ip(⽐如 172.18.42.56) 这个虚拟 IP 地址。然⽽,如果 A 是拿着这个IP作为长连接服务,频繁对B发包。这个时候,B服务下掉了。下掉后,kube-proxy 组件,将从 iptables 中删除 B 服务的iptables 规则,也就是说,172.18.42.56 这个虚拟 IP 从 iptables 中删除了。此时,A 如果 还拿着这个 IP 发包,那么因为 集群内已经缺失了这个虚拟 IP 的记录,必然导致这部分流量,将穿越 iptables 规 则,发到上层的⽹关。如果这个流量⾮常⼤的话,将对⽹关路由器造成⾮常⼤的冲击。
这个是切实存在的⼀个问题,也是我们之前遇到的⼀个问题。这个问题,你只能去⼿动修改iptables规则来处理。 因为 kube-proxy 也在修改 iptables 规则,所以,这个操作存在⼀定风险性,需要谨慎操作。
劣势3:最重要的,⽹络的性能损耗严重。
这个问题,要从2个⽅⾯看:
①:基本上做 K8S 和 Docker 的同学都知道。flannel vxlan 和 calico ipip 模式 这种虚拟⽹络,在容器跨宿主机通 信时,存在包的封包和解包操作,性能损耗⼤。
②:K8S 内 有⼤量服务和容器的时候,iptables 会⾮常多,这对⽹络的性能损耗也是很⼤的。
容器和宿主机平⾏⽹络打通通常会遇到的问题
基于上⾯的内容,很多⼈开始尝试将容器⽹络和公司所有物理机的⽹络打通,也就是形成⼀个平⾏⽹络体系。这个 体系,去除了封包和解包操作,也不再使⽤ kube-proxy 组件⽣成iptables规则。⽹络的性能⾮常⾼。
打通平⾏⽹络的⽅案又很多,⽐如 Calico BGP、Linux Bridge、Linux Macvlan、Linux IPVlan 等等。
这⼏个⽅案的特点如下:
| ⽅案/特点 | 复杂度 | 机房改造成本 | 运维成本 |
|---|---|---|---|
| calico bgp | 很⾼ | 很⾼ | ⾼ |
| linux Bridge | 低 | 无 | 低 |
| linux ipvlan | 很低 | 无 | 很低 |
| linux macvlan | 很低 | 无 | 很低 |
总体来说:
calico bgp 这种⽅案:实现成本⽐较⾼,需要整个公司的基础⽹络架构的物理设备(交换机或路由器)⽀持 BGP 协议才⾏。⽽且,⼀旦出现问题,排除的复杂度也⾼,需要公司的⼈很懂才⾏。我个人觉得,如果公司的研发和网络的掌控力没有达到一定程度的话,不建议采用这种方式。
linux bridge:这种⽅案的成本较低,不过需要将物理⽹关挂到⽹桥下,如果是单⽹卡的物理机,这个操作会断 ⽹,建议多⽹卡环境进⾏操作。
linux macvlan:这种⽅案成本很低,需要⽹卡⽀持混杂模式(⼤部分⽹卡都是⽀持的)。混杂模式需要⼿动开启。
linux ipvlan:这种⽅案成本很低,和 Macvlan 很像。区别是不同 IP 公⽤ mac 地址,性能可能相对 macvlan 好⼀ 些,具体其优势不做细谈。
打通容器和宿主机平⾏⽹络,其实也会存在⼀些问题,需要提前规划好。⽐如,是直接2层⽹络打通,还是3层⽹ 络打通?2层⽹络打通,可能既需要⼀个强⼒的交换机设备,也需要防⽌⼴播风暴产⽣。如果是3层⽹络打通,意 味着多⽹段,⽽多⽹段的情况,每新增⼀个IP段,宿主机都要进⾏⼀个路由表的处理操作,这倒也不是⼀个⿇烦的 问题。
另外,macvlan、ipvlan 对操作系统的内核版本都有⼀定的要求。内核版本⽀持不好的情况下,会遇到各种各样的 异常问题,不好排查。⽐如 macvlan 在 Linux 4.20.0 这个内核版本上,就有很多问题,⽐如:
1 | kernel:unregister_netdevice: waiting for eth0 to become free. Usage count = 1 |
ipvlan和macvlan⽅案实施遇到的容器与宿主机互访问题
我⾸先考虑的⽅案,就是实施成本要低、维护简单,⽬的不变,也就是投⼊产出⽐要⾼。所以,macvlan 和 ipvlan 就是⾸选。
但是,macvlan 和 ipvlan 都有⼀个共同的特点,就是虚拟 ip 所在的⽹络,⽆法直接和宿主机⽹络互通。简单来 ⾸,利⽤这2个模型,将虚拟 ip 加⼊到容器⾥后,容器⽆法直接 ping 通宿主机。这个不是bug,⽽是这2个⽹卡虚 拟化技术,在设计之初,就是这样的。
但是,实际情况下,我们不太可能不让容器的⽹络访问宿主机的⽹络。所以,这个问题,必须要解决。
要解决这个问题,使⽤ macvlan 的话,有⼀个⽐较好的天然解决⽅案。就是使⽤ macvlan 也在宿主机上⽣成⼀个 虚拟⽹卡。这样⼀来,容器⽹络就可以和宿主机互访,操作上就是⼀⾏命令的事⼉。但是!!我们本机利⽤苹果本 虚拟机调试是没有问题的,⽤ KVM 调试,但 Pod 变化触发容器⽹络销毁和新建这种变化时,宿主机就⽆法访问容 器⽹络了,⽽且,在同⼀个宿主机上,宿主机对其内的有些容器可以访问,有些容器不能访问,⾮常奇怪,这个问 题,可能在物理机上不⼀定存在,但是在调研阶段,我们必须要考虑其在线上物理机环境也⽆法实施或者后续遇到 类似问题的情况。所以,我们尝试更换了多个操作系统的Linux内核版本,问题依然,只能另寻他法。
使⽤ ptp 优雅的解决使⽤macvlan(或ipvlan)时容器和宿主机互访问题
解决互访问题,前⾯提到的⽅案是,如果使⽤macvlan可以⽤其在宿主机虚拟⼀个⽹卡出来配置⼀个和宿主机的平 ⾏⽹络IP。这个弊端前⾯提到了很重要的⼀部分,另外还有⼀部分没有提到,就是IP资源浪费的情况。相当于每个 主机都需要多⽤⼀个IP地址。
需要⼀个⽅案,可以通⽤的解决 macvlan 和 ipvlan 这种容器和宿主机⽹络⽆法互访的问题。
解决这个问题,我们可以借助 veth pair 来完成。其原理是,创建⼀对 veth pair,⼀端挂⼊容器内,⼀端挂⼊宿主 机内。如图:
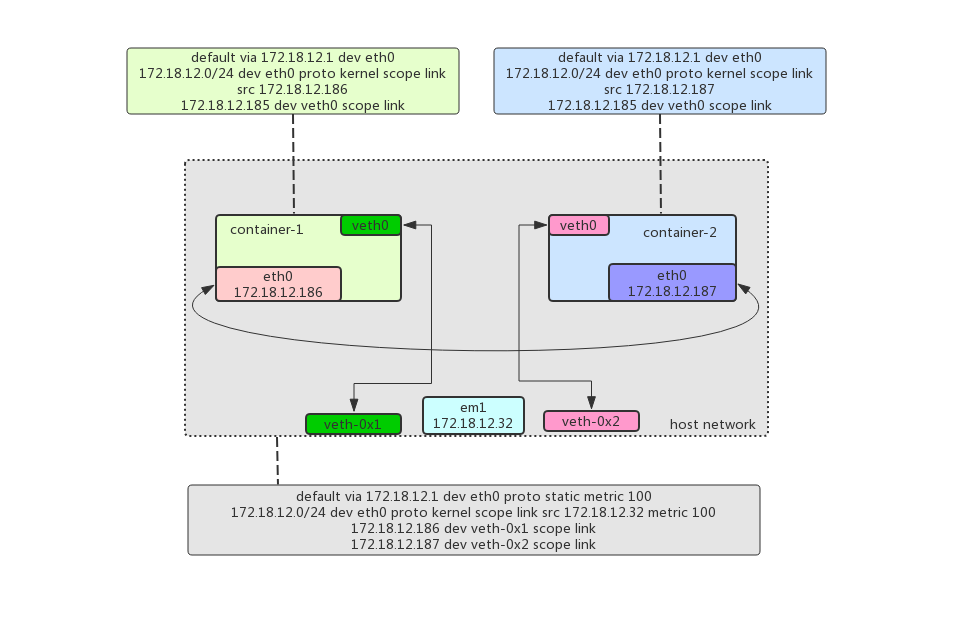
如上:
①:借助 ipvlan 或 macvlan 在 em1 上创建2个虚拟⽹卡,然后分别加⼊到 container-1 和 container-2 中,容器内 ⽹卡命名为 eth0,且 IP地址 和宿主机平⾏。
②:上⾯的操作完成后,容器之间可以互访,但是,容器和宿主机⽆法互访,这是 ipvlan/macvlan 的制约。
③:创建 2 个 veth-pair 对,⼀对加⼊宿主机和容器 container-1 中(容器端叫 veth0,宿主机端为 veth-0x1),另 外⼀对加⼊宿主机和容器 container-2 中(容器端叫 veth0,宿主机端为 veth-0x2),然后在容器内创建指向到宿 主机⽹卡的路由表规则,于此同时,在宿主机上,也要建⽴指向到容器⽹络的路由表规则。
综上,可以完成容器和宿主机⽹络互访。
使⽤这种⽅案有⼏个有点:
①:CNI 插件使⽤ macvlan 或 ipvlan 都没有关系。
②:不需要借助 macvlan 在宿主机上虚拟⽹卡出来,因为这种⽅案,不具备通⽤性,⽽且,并不稳定(在某些vm 主机的场景下)。 其实,上述⽅案的实现,便是 K8S CNI 插件 ptp 的原理。
IPAM的使⽤
上⾯的操作完成后,解决了 CNI 的问题。剩下的,就是 IPAM 的问题。在整个流程中,CNI 插件主要负责⽹络的 定制,⽽ IP 如何获取,并⾮ CNI 的⼯作内容,它可以通过调⽤ IPAM 插件来完成IP的管理。
IPAM 插件有很多,最简单的,是 K8S CNI 官⽅提供的 host-local IPAM 插件:https://github.com/containernetworking/plugins 。CNI 的插件,K8S 官⽅也有提 供:https://github.com/containernetworking/cni 。
我们在实际测试过程中发现,K8S 的 CNI 插件,在 kubelet 1.13.4 版本上存在问题,报找不到 cni 名称的问题。所 以,我将 lyft 的⼀个开源项⽬ cni-ipvlan-vpc-k8s 改造了⼀下(主要是解决 ptp 插件设置默认路由规则失败导致 CNI整体调⽤失败的问题,此问题不⼀定在所有场景中存在,需要使⽤者结合⾃⼰业务来处理)。
下⾯是⼀个 CNI 配置⽂件的样例:
1 | //cat /etc/cni/net.d/10-maclannet.conflist |
1 | { |
配置⽂件说明:插件是2个,⼀个是名字为 myipvlan 的插件,类型为 ipvlan(也就意味着 kubelet 会去 CNI 插件 ⽬录找名为 ipvlan 的可执⾏⽂件),⼀个名为 unnumbered-ptp。
其中,ipvlan 插件要配置的 IP,会从 CNI 插件⽬录,寻找名为 host-local 的可执⾏⽂件来获取 IP 地址。
再次说明,ipvlan 和 unnumbered-ptp 是基于 lyft 的⼀个开源项⽬ cni-ipvlan-vpc-k8s 改造过的。
