KubeDNS简述
KubeDNS,是K8S官方推荐的DNS解析组件之一,从 K8S 1.11 开始,K8S 已经使用 CoreDNS,替换 KubeDNS 来充当其 DNS 解析的重任。
KubeDNS的前身,是 skyDNS,这个组件,会把 DNS 的解析记录等数据,存储到 K8S 所使用的 etcd 集群中,我们这里不讨论这个,仅讨论现今的 KubeDNS,KubeDNS,并不把 DNS 的解析规则存储到 etcd,而是放到进程的内存中,当 KubeDNS 的服务 POD 重启后,会重建一遍 DNS 规则到内存。
在前篇,我们已经了解了 K8S 中,DNS 解析的原理,本篇,我们侧重 KubeDNS 本身。包含下面几个点:
- KubeDNS 服务,包含了哪些组件,职责是什么?
- KubeDNS 是如何区分 K8S 内部域名还是外部域名的?
- KubeDNS 如何配置上游DNS服务器?
- KubeDNS 如何配置自定义域名解析?
- KubeDNS 解析 K8S 内部域名的的实现原理是什么?
- KubeDNS 如何做弹性扩缩容?
KubeDNS组件构成
在 K8S 中,KubeDNS 的实例是 POD,配置一个 KubeDNS 的 Service,对 KubeDNS 的 POD 进行匹配。在 K8S 的 其他 POD 中,使用这个 Service 的 IP 地址,作为 /etc/resolv.conf 里 nameserver 的地址,从而达到 POD 里使用 KubeDNS 的目的。这是 K8S 的默认行为,我们不需要手动干预。
其实严格来说,是 Service 匹配 Endpoint,因为 POD 创建之后可能会有IP,但此IP可能是一个 POD 非 完全Ready 状态下的 IP,理论上,这种 IP 是无无法提供服务的,所以,说 Service 匹配 Endpoint 更合适一些。
然而,KubeDNS POD 是由 Deployment 控制启动的,POD 中,并非只有一个容器。KubeDNS 的配置,是使用的 ConfigMap,总的来看,有2个主要资源:
一个标准 KubeDNS 的 Deployment
1 | apiVersion: extensions/v1beta1 |
从这个 Deployment 可以看到2个重点:
- KubeDNS 使用 名称为 kube-dns 的 ConfigMap 作为其配置(ConfigMap没有,POD也可以运行)。
- KubeDNS 使用了3个容器,组合提供DNS服务。
KubeDNS组件构成及实现
KubeDNS,使用3个容器组合服务,分别是:dnsmasq、kube-dns、sidecar,这3者,职责不同,整个DNS架构组成如下:
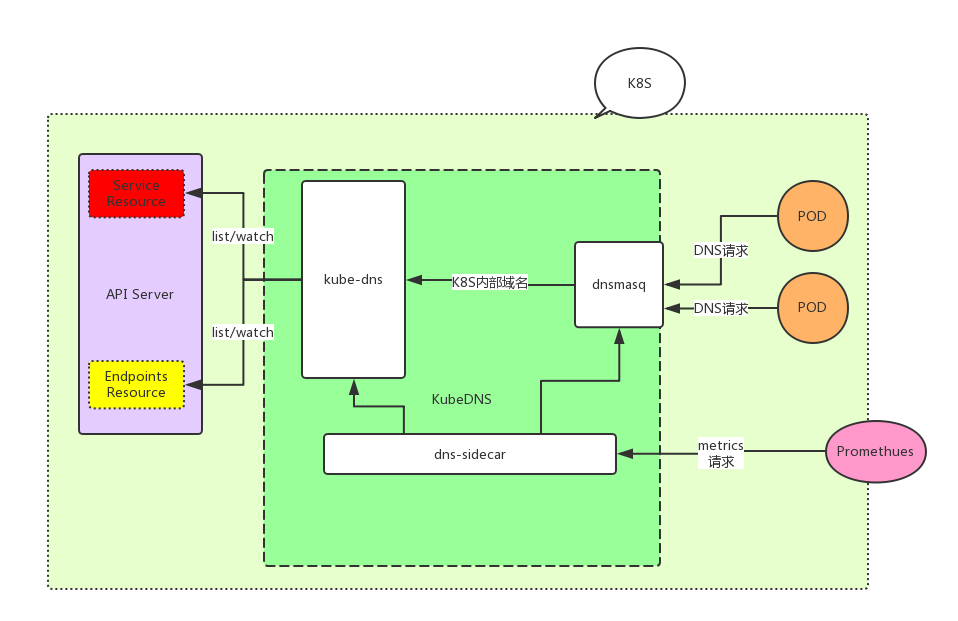
POD的DNS请求打到 dnsmasq 容器的53端口,dnsmasq 决定此请求时自己处理,还是转到 kubedns 容器处理。各组件具体职责:
dnsmasq 容器
dnsmasq 容器:负责整个 KubeDNS 的请求入口,53端口,就是它开放的,因此,在 K8S 中,内部域名和外部域名请求处理的区分,也是 dnsmasq 来做的。它充当 DNS 的请求入口,有几个作用:
- 充当 DNS 请求入口。
- 区别 K8S 内部和外部域名走不通的策略。
- DNS 缓存,进行过DNS请求后的域名会进行缓存,提高DNS请求效率。
在此容器的启动参数包含下面部分:
1 | - --server=/cluster.local/127.0.0.1#10053 |
这个参数说明,cluster.local 结尾的域名(这种是 K8S 的内部域名,不理解为什么这种是 K8S 内部域名的,可以翻看之前的文章),dnsmasq 进程会把此 DNS 请求,转发到 127.0.0.1:10053 端口上。而 10053 端口,是 kube-dns容器进程,正是监听的 10053 端口。所以说, dnsmasq 通过 - –server=/cluster.local/127.0.0.1#10053 这个配置,来决策 K8S 内部的域名的 DNS 请求,往 kube-dns 容器转发。
dnsmasq 先解析本地 /etc/hosts 文件
再解析 /etc/dnsmasq.d/*.conf 文件
然后解析 /etc/dnsmasq.conf
最后解析自定义上游DNS的部分,也就是 /etc/dnsmasq.conf 中 resolv-file 的字段部分,一般我们将 resolv-file 字段配置为 /etc/resolv.conf。
dnsmasq为KubeDNS提供缓存加速能力
KubeDNS 缓存,其实,利用的便是 dnsmasq 具备的缓存能力。另外,缓存,在 KubeDNS 中非常重要,能最大程度的发挥 DNS 响应效率,我们通过一个实际例子测试一下:
第一次请求一个不存在的域名时,第一次 DNS 请求:
1 | [root@test8-5646b97977-p6z8p /]# dig jjjjjjjj1212121212.com |
请求耗时 864ms,耗时相当长。
再次执行 DNS 请求:
1 | [root@test8-5646b97977-p6z8p /]# dig jjjjjjjj1212121212.com |
请求耗时仅仅1毫秒。加速效果相当明显。
dnsmasq 容器内的进程组成及职责
dnamasq 容器内,其实有2个进程,一个是 dnsmasq-nanny,一个是 dnsmamsq。其实,我们上面看到的 KubeDNS 的 deployment 里关于 kube-dns 容器的配置里的相关参数,并不是直接对 dnsmasq 进程生效的,而是对 dnsmasq-nanny 进程生效的。
dnsmasq-nanny 进程,是 dnsmasq 容器进程的1号进程,是保姆进程,而 dnsmasq 进程,就是由 dnsmasq-nanny 进程 fork 出来的,dnsmasq-nanny 具备 fork、restart 及传递配置参数给 dnsmasq 进程的能力。
我们可以通过进程树来看 dnsmasq-nanny 和 dnsmasq 的关系。
1 | // 查看进程树 |
既然 dnsmasq-nanny 是保姆进程,其有几个重要参数:
1 | // dnsmasq-nanny 进程的配置目录,这个目录,是需要挂载 configmap 类型 Volume 到此目录的 |
dnsmasq 容器负责让KubeDNS更新配置生效
更新配置很简单,只需要更新名称为 kube-dns 的 ConfigMap 的内容,即可,但这里我们主要从源码角度,讲一下原理是什么。首先再次明确一遍,KubeDNS由多个组件构成,但真正负责处理配置更新的,只有 dnsmasq 容器的 dnsmasq-nanny 进程。
我们通过部分源码,也可以看出来,dnsmasq-nanny 是 如何 重启 dnsmasq 进程的:
1 | // dns/pkg/dnsmasq/nanny.go#169 |
那么,配置是什么时候产生变化的呢?
dnsmasq-nanny 进程处理配置变化的方式比较粗暴,如果设置了 -configDir 配置目录的话,此进程会间隔 10s ,进行一次配置检测,如果发生变化,就 重启 dnsmasq。
1 | // dns/cmd/dnsmasq-nanny/main.go#72 |
1 | // dns/pkg/dns/config/sync.go#81 |
我们看看,是如何判断文件发生变化的
1 | // dns/pkg/dns/config/sync.go#99 |
综上:dnsmasq-nanny 保姆进程,会一直检测自己参数 -configDir 配置的目录里的文件是否发生了变化,判断的逻辑是:每隔10秒钟,读取一次这个目录下的所有【配置文件数据】(一个Map,key为文件名,值为文件内容),用 sha256 计算一次摘要,作为这个目录下所有数据的版本。然后记录下来,下次的时候执行同样的逻辑,如果发现版本不同,则认为配置文件发送了变化。然后将得到的【配置文件数据】重新解析为 dnsmasq-nanny 的配置数据,最后,杀死 dnsmasq 进程,启动一个系的 dnsmasq 进程。但是,这里边,有几个细节点:
第一:重启 dnsmasq 的方式,先杀后起,方式台粗暴,很可能导致这个时间点的大量DNS请求失败。不优雅。
第二:dnsmasq-nanny 检测数据变化的方式,这种方式就有2个值得注意的问题:
①:官方是,每次遍历目录下的所有文件,然后,使用 ioutil.ReadFile 读取文件内容。如果目录下文件多,可能导致,你遍历的同时,配置文件也在变化,你遍历的速度和文件更新速度不一致,导致,读取的配置,并不一定是最新的,可能你遍历完,某个配置文件才更新完。那么此时,你读取的一部分文件数据并不是和当前目录下文件数据完全一致,本次会重启 dnsmasq。进而,下次检测,还认为有文件变化,到时候,又重启一次 dnsmasq。这种方式不优雅,但问题不大。
②:文件的检测,直接使用 ioutil.ReadFile 读取文件内容,也存在问题。如果文件变化,和文件读取同时发生,很可能你读取完,文件的更新都没完成,那么你读取的并非一个完整的文件,而是坏的文件,这种文件,dnsmasq-nanny 无法做解析,不过官方代码中有数据校验,解析失败也问题不大,大不了下个周期的时候,再取到完整数据,再解析一次。
kube-dns服务容器及实现原理
讲完 KubeDNS 服务的 dnsmasq 容器,现在开始 kube-dns 容器。kube-dns 容器,最主要的职责,就是负责解析 K8S 的内部域名记录,这个解析,它监听了 10053 端口,本质上,kube-dns 是接受 dnsmasq 请求的( dnsmasq 容器负责处理所有 DNS 请求,对于 K8S 的内部域名请求,转发给 kube-dns 来处理)。
kube-dns 的进程职责是,监视Kubernetes master上 Service 和 Endpoint 的改变,并在内存中维护 lookup 结构用于服务DNS请求。
此容器启动参数为:
1 | - --domain=cluster.local. |
–domain:表示在哪个domain下创建域名记录。
–dns-port:这个是启动端口。
–config-dir:这个是使用的配置,通常来说,我们的 KubeDNS POD,会使用 ConfigMap,将配置挂载到容器内的 –config-dir 指定的目录上。
这里打算源码层面,追踪一下具体实现,但不打算从头追到尾,这样篇幅太大,只罗列一部分核心点。核心点内容包括:
- kube-dns 容器,都是监听的哪些 K8S 资源数据,作为域名记录的解析依据?
- kube-dns 使用什么技术或数据结构实现内存级数据查询的?
- 如果 K8S 有 Service 资源,但没有对应的 POD 资源,域名解析是否还能成功?
kube-dns容器监听哪些K8S资源?
我们知道,K8S 内部域名的 DNS 解析,得到的是 Service 的 IP 地址。kube-dns 肯定监听了 Service 资源了,为的是,处理内部域名映射到 Service 的 IP 地址。从源码看,其实 kube-dns 容器,其实监听了2个资源,分别是:
- Service 资源
- Endpoints 资源
至于为何还需要监听 Endpoints 资源,我们一步步解开谜底
1 | // 开启一个 KubeDNS 处理实例 |
1 | // setServicesStore 负责处理 Service 资源 |
我们看一下,如果 K8S 有 Service 资源创建出来,kube-dns 容器都做些什么
1 | // 针对 K8S 中 Service 资源的创建,做处理 |
上面提到,Service 的创建操作,会涉及到 newHeadlessService 无头服务域名记录的操作,具体如下:
1 | // 创建无头服务Service的域名记录 |
如果 Service 下没有Endpoints,不处理,一旦有 Endpoints 产生,立即生成域名记录:
1 | // 根据 Endpoints,创建无头服务记录 |
kube-dns使用何种数据结构实现DNS检索?
参看后面附录
dns-sidecar容器
dns-sidecar容器职责简述
这是其实是一个健康监测容器,检查 dnsmasq 和 kube-dns 2个容器的监控状态。先回顾一下 sidecar 容器的参数
1 | - args: |
这个容器,主要职责是探测 dnsmasq 以及 kubedns 服务的状态。但从上面 deployment 的参数,看不出太多东西,从源码角度可以看到更多:
1 | // sidecar 容器的默认启动参数 |
sidecar 容器,开放了一个 10054 端口访问,这样一来,我们可以通过 Prometheus 来收集 sidecar 的数据,另外需要说明的是,其实 sidecar 容器开放的 metrics 接口,暴露出来的数据,是 sidecar 探测 dnsmasq 以及 kube-dns 两个目标后,汇总的数据,数据包括:
- 基本的 Go 应用性能数据(协程数量、CPU使用、打开的最大文件描述符数、内存使用等)
- dnsmasq 容器发生的错误数
- dnsmasq 容器已经发生的 DNS 缓存驱逐次数
- dnsmasq 容器已经发生的 DNS 缓存插入次数
- dnsmasq 容器缓存未命中次数
- dnsmasq 域名解析失败次数
- 探测到的 dnsmasq 延迟时间
dns-sidecar 是如何做检测的
sidecar 的探测周期,默认为 5s 一次。–probe 指定了探测参数,比如:
1 | - --probe=kubedns,127.0.0.1:10053,kubernetes.default.svc.cluster.local,5,A |
表示:探测的服务“标签”为 kubedns,使用域名 kubernetes.default.svc.cluster.local ,将 A 记录类型的DNS解析请求,打到 127.0.0.1:10053 上。
注意:这里的“标签”,是为某个DNS服务目标,打的一个标识而已,后边,这个“标签”会用到。主要是为了方便 通过 dns-sidecar 的 metrics 接口,访问到具体的某个“标签”的DNS服务的健康指标。
指定多个 –probe 参数,则都会探测多个目标服务
1 | // dns/pkg/sidecar/server.go#43 |
追一下是如何进行具体的DNS探测的:
1 | // dns/pkg/sidecar/dnsprobe.go#74 |
具体的 DNS 探测动作:
1 | // dns/okg/sidecar/dnsprobe.go#111 |
KubeDNS 服务弹性水平伸缩
官方推荐方案:cluster-proportional-autoscaler
关于 KubeDNS 服务弹性伸缩,官方已经给出了一套比较简单的弹性水平扩缩容解决方案,下面是一套推荐的配置,用它来部署 KubeDNS 的 autoscaler:
1 | apiVersion: extensions/v1beta1 |
我们看几个关键参数:1
2
3
4
5
6- --namespace=kube-system // autoscaler 配置所在的命名空间
- --configmap=kubedns-autoscaler // autoscaler 的 configmap 配置名称
- --target=Deployment/kube-dns // 表示要弹性伸缩的目标
- --default-params={"linear":{"nodesPerReplica":10,"min":2}} // 默认配置,这个配置可以由 configmap 覆盖
- --logtostderr=true
- --v=2
我们可以定义 configmap 来配置 kubedns-autoscaler 的具体参数,configmap 中可以配置的内容如下:
cluster-proportional-autoscaler 线性配置方式
1 | data: |
1 | min:表示目标最小实例数,也就是 KubeDNS 最少的实例数量。 |
整体来看,由下面这个公式,的出来最大的DNS实例数:
1 | replicas = max( ceil( cores * 1/coresPerReplica ) , ceil( nodes * 1/nodesPerReplica ) ) |
cluster-proportional-autoscaler 梯度配置方式
省略,也可以查看官方文档。
cluster-proportional-autoscaler 水平扩容是如何实现的
- 独立部署 cluster-proportional-autoscaler
- autoscaler 从 APIServer(也就是K8S Master)拉取集群的核数和节点数,并根据这2者,确定一个 POD 最大实例数。
- 可以通过 configmap 配置 autoscaler 的参数,而不需要 重启 autoscaler 实例。
- autoscaler 提供了【线性】及【梯度】2种扩容方式。
这里边有一个小问题:通常,我们使用 ConfigMap 都是讲 ConfigMap 作为 volume ,Mount 到容器上,而 autoscaler 并没有使用这种方式,而是监听了K8S资源(通过 –configmap 及 –namespace 配置)从中获取配置,这种方式非常快而且高效,且不需要重启 autoscaler 实例。
扩容项目为:https://github.com/kubernetes-incubator/cluster-proportional-autoscaler
cluster-proportional-autoscaler 不足之处
基本上从上面可以知道,这个 扩容器,比较简单,最多就是根据集群的核数,以及节点数来配置最大实例数,其实这个扩缩容,并没有完整的实现出来,官方的意思是,Kubernetes 设想的 Horizontal Pod Autoscaler(https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/) 是一个顶级的资源,需要根据集群中容器的CPU指标来衡量一个合理的值,但是当前这个 cluster-proportional-autoscaler ,仅仅是一个 DIY 实现,所谓的 DIY 实现,意思就是,你得自己手动来控制(比如通过更改 configmap 的方式),它并没有收集集群中容器的CPU利用率等数据,仅仅是一个比较粗略的水平调度实现而已。
Questions
到底dnsmasq和kube-dns,谁提供的DNS上游能力?
DNS 上游查询能力,也即是我们访问 非 K8S 内的域名,比如 youku.com,是 dnsmasq 向上游 DNS 服务器查询的,还是 kube-dns 来做的?
首先,dnsmasq 是 K8S 内 DNS 服务的入口,它决定内部的域名往 kube-dns 转发,其他的域名,往上游 DNS 服务器转发,然后将结果根据域名的TTL做缓存,加速DNS查询。
从上面文章的分析看,应该就是 dnsmasq 来上游查询处理的,但是,从 kube-dns 源码上看,其实 kube-dns 本身,也是具备提供 DNS 上游查询能力的。我们需要具体来看,这个上游查询,是谁来做的。
在 K8S 中,我们这样设置 DNS 上游,需要在 名为 kube-dns 的 ConfigMap 中来做。比如:
1 | apiVersion: v1 |
上游DNS服务器字段:upstreamNameservers。
既然是需要配置 ConfigMap 来使配置生效,那么就看一下,是谁 使用了这个 ConfigMap 就行了。所以,我们回顾文章最开始部分的 deployment,看看谁将 ConfigMap 作为 Voloume 挂载到自己容器里使用就行了。
我们能够看到,使用 ConfigMap 的,有2个容器,分别是:
①:dnsmasq 容器
②:kube-dns 容器
kube-dns 容器使用这个 ConfigMap,肯定是可以根据其配置,使用配置中的 upstreamNameservers 中的地址来决定域名解析请求往何处转发的。但问题在于,它有这个能力,但不代表上游解析,真的由它来做。
这里边需要注意的是,dnsmasq 容器也使用了这个配置,但并不是 dnsmasq 容器的 dnsmasq 进程直接使用的,而是 dnsmasq 容器中的 dnsmasq-nanny 进程来使用的,这个进程本身就是保姆进程,当 ConfigMap 变化后,dnsmasq-nanny 进程,便会解析配置,将配置中的 upstreamNameservers、stubDomains 内容,转换为 dnsmasq 进程能够识别的参数,然后杀死 原来的 dnsmasq 进程,启动一个新的。
所以,在 KubeDNS 服务中,提供上游DNS解析能力的,是 dnsmasq 容器,而不是 kube-dns 容器。
附录1:kube-dns使用何种数据结构实现DNS检索
后续有时间再补充。
